Ansibleとは (Ansible超入門)
どうも、ITコンサルタントのShoheiです。
今日はAnsibleについて解説していきましょう。
タイトルに記載の通り、超入門編です。以下のような人を対象にしています。

Ansibleって何?
早速、定義的なものを探るために公式ページ*1をみてみましょうか。
素敵ですね。
"unraveling the mystery of how work gets done" =仕事がなされる謎を解明してくれるらしいです。
もう少し地に足ついた説明をば。
このままだと壮大すぎてわからないので、Wikipediaさん*2に聞いてみました。
Ansible(アンシブル)は、レッドハットが開発するオープンソースの構成管理ツールである。サーバを立ち上げる際、あらかじめ用意した設定ファイルに従って、ソフトウェアのインストールや設定を自動的に実行する事が出来る[1]。特に大規模なコンピュータ・クラスターを構築する時に、時間の短縮やミスの削減に有用である。
なるほど、構成管理... もう少し詳しくみていきましょう。
従来の構成管理
構成管理とは、端的にいうとITシステムを構築したり管理したりすることです。ここでの管理対象にはサーバーのIPアドレスやホストから、個々のConfig, SWの設定レベルまで含まれます。
では構成管理の実態はどうでしょう。下の絵をご覧ください。結構いろんな企業で起きている状況かと思います。

絵のようなサーバ3台程度のシステムならばまだなんとかなるかもしれません。
では、1000台程度の大規模システムになるとどうでしょう。もう人力だけに頼った管理では限界ですよね。
たとえエクセルシートの更新が義務付けられていたとしても、人の手で更新であれば必ずと言っていいほど抜け漏れが発生します。
自分はポータル上で構成管理していた経験が有りますが、これも同様でした。特に複数人で管理していたので、誰がどんな変更をしたかもわからず、気づいたらぐちゃぐちゃ、なんてこともよく有りました。
構成管理が徹底できないと、システム全体像の把握困難になり、開発時の依存性調査などが正確にできなくなります。またシステム障害発生時の切り分けも難しくなります。
さらに、例えば作業ミスなどで、サーバ1台だけアプリケーションのバージョンが古く連携ができない状態になっていても、問題が起きるまで把握できません。
Infrastracture as a Codeの世界へ
ではここからはAnsibleを念頭に、構成管理ツールを導入した世界を見ていきましょう。
ITの構成情報は構成管理ツールに記載します。Ansibleでは、その記載はInventoryと呼ばれるファイルに行います。
またアプリケーションをデプロイしたり状態チェックをするといった、今まで手順書に記載していた内容(タスク)も、全てコードで記載します(playbookと呼ばれます)。Ansibleの場合、これらはYAML形式で保存されます。
下の図のように、inventoryに記載したサーバに対して、playbookに書いてある内容を実行することで、変更作業を行うことができます。
例えばinventoryで定義したwebというグループのサーバについてだけ、playbookの内容を実行してね、というやり方もできます。

Infrastructure as a Code
こうすることにより、構成情報や変更作業を全てコードで管理する世界にシフトすることができます。
これにより嬉しいことは、デプロイなどの手作業で行なっていたことが自動化できるといった点もそうですし、ソフトウェア開発で培ったベストプラクティスを構成管理(特にインフラ)にも適用できるという点も有ります。変更時のレビューや、バージョン管理などが容易にできるようになるということです。
このような、インフラの世界の管理や変更までコードでやってしまおう、という考え方のことを、Infrastracture as a Codeと言います。
Ansibleの強み
最後に、Ansibleの強みをいくつか紹介していきましょう。
エージェントレス
変更対象・管理対象のサーバに専用エージェントを導入する必要は有りません。
基本pythonが使えて、sshが可能であれば利用可能です。
シンプル
YAMLファイルを使うので、シンプルに記載することができます。
冪等性がある
一番重要なポイントなのでしっかり解説します。
冪等性というのは、たとえ間違えて繰り返し実行しちゃったとしても目的の状態になる、というものです。
例えばシェルスクリプトの以下のコマンドについて考えてみましょう。
$ for server in `cat LIST.txt`;do ssh server "echo "add">> test.txt; sleep 1";done
この場合、LIST.txtに書かれたサーバが持つtest.txtというファイルの最後の行に "add"という文字列を追加する、というコマンドですが、二回実行するとaddという文字列が二行追加されてしまいます。
一方でAnsibleでは多くのモジュールで冪等性が保証されています。
冪等性のある動作では「コマンドを実行すること」ではなく「対象を目的の状態になっているかどうか」が保証されるので、誤って二回実施してしまったとしても、また誤って手動で何か間違った変更を加えたとしても、Ansibleからplaybookを実行することで対象をあるべき状態に戻すことができます。
その他の構成管理ツール
他の代表的なツールとしては、Chef, Puppetなどがあります。比較記事も出てたりするので、興味があれば見てみてください。
まとめ
今日は構成管理ツール、Ansibleについて解説しました。
次回、もう少し具体的にAnsibleをいじってみましょう。
統計検定のススメ
どうもkoheiです
一気に寒くなりましたね
今日は資格「統計検定」のお話をします。

統計検定とは?
統計検定とは、日本統計学会が認定する統計学に関する知識や活用力を評価する試験です。2011年に発足したばかりで、比較的まだ歴史の浅いものになります。試験は難易度に応じて4級~1級まであります。
自分は統計検定2級までは取得しました。まだ準一級以上は勉強中の身です。
データサイエンティストを示す資格はなに?と聞かれたときに、明確にこれ持ってればデータサイエンティストだよっていうものはないですが、統計検定はその中の一つには含まれると思います。
試験の種別試験内容
| 統計検定 1級 |
実社会の様々な分野でのデータ解析を遂行する統計専門力 「統計数理」と「統計応用」の二種類の試験がある。 |
| 統計検定 準1級 | 統計学の活用力 ─ データサイエンスの基礎 |
| 統計検定 2級 | 大学基礎統計学の知識と問題解決力 |
| 統計検定 3級 | データの分析において重要な概念を身に付け、身近な問題に活かす力 |
| 統計検定 4級 | データや表・グラフ、確率に関する基本的な知識と具体的な文脈の中での活用力 |
試験を受ける方法は次の二通り
- 年二回(例年6月と11月)の試験を指定の会場で受験する
- CBTと呼ばれるコンピュータ試験を申し込んで受験する(2,3級のみ)
料金は下記の通り。コンピュータ受験のほうがちょっと高いですが、自由に試験タイミングを選べます。
| 種類 | 年二回の会場受験 | CBT方式 |
| 統計検定 1級 | 10000円 (統計数理+統計応用の場合。一つなら6000円) |
無し |
| 統計検定 準1級 | 8000円 | 無し |
| 統計検定 2級 | 5000円 | 7000円 |
| 統計検定 3級 | 4000円 | 6000円 |
| 統計検定 4級 | 4000円 | 無し |
2級まで、コンピュータ受験可能ということで、2級まではすべて選択式の問題。
準一級からは記述式の問題も含まれます。
なんで受けたの?
データサイエンスというお仕事柄、統計学が関連するシーンは非常に多いです。
例えば、
商品Aについて11月2週間だけキャンペーンを実施したが、既存の場合と売り上げに差があったのか知りたい。効果があるなら今後も続けたい
といったとき、単純に平均値を比較して売り上げが高かったとしても、もともと売り上げ幅にばらつきがあり、たまたまその2週間だけ売り上げが高かった可能性もあります。
そこで使うのが統計学です。これまでの売り上げのばらつきまで考慮して、偶然2週間だけ売り上げが伸びたのか、それとも確かな差が出ているので今後キャンペーンを続けるべきか、判断することができます。
このように大量データから平均、分散、標準偏差、中央値、確率分布等、統計知識を使った判断が必要になるケースが多く、基本知識として必要な部分が多いと思ったからです。
どんな問題があるの?
過去の問題は公式サイトから閲覧可能です。
統計検定2級に関していえば、おおよそは
- 箱ひげ図、散布図といった図表の読み取り
- 期待値や確率計算や正規分布、二項分布といった確率分布に関する問題
- 仮説検定
- 回帰を使った予測
- 統計ソフトの結果の読み取り
などが項目として挙げられます。
どうやって勉強したの?
もともと大学時代に勉強していたこともあり、ひたすら過去問にチャレンジしました。
![日本統計学会公式認定 統計検定 2級 公式問題集[2015〜2017年]](https://images-fe.ssl-images-amazon.com/images/I/51XhPG4IbXL._SL160_.jpg "日本統計学会公式認定 統計検定 2級 公式問題集[2015〜2017年]")
日本統計学会公式認定 統計検定 2級 公式問題集[2015〜2017年]
- 作者: 日本統計学会
- 出版社/メーカー: 実務教育出版
- 発売日: 2018/03/22
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
が、これは事前に統計知識がある人向けです。あんまりオススメしません。
(amazonのレビューも低め。。。)
例えば、

をみて、「あーこれ、正規分布ね。」
くらいは知ってる前提だと思います。
正規分布とかよくわかりません、というところから勉強するには
まずこうした基礎知識を勉強する必要があります。
かといって、統計学の教科書とか見だすと数式の羅列であまり面白くありません。
統計学は当然数式の羅列な部分はあるのですが、確率という概念を扱う以上、まずイメージの湧きやすい入門書から入って感覚的につかむことをお勧めします。
ネット上でも有名な本としては、このあたりでしょうか
")
マンガでわかる統計学 素朴な疑問からゆる~く解説 (サイエンス・アイ新書)
- 作者: 大上丈彦,メダカカレッジ,森皆ねじ子
- 出版社/メーカー: SBクリエイティブ
- 発売日: 2012/01/17
- メディア: 新書
- 購入: 6人 クリック: 14回
- この商品を含むブログ (6件) を見る

- 作者: 小島寛之
- 出版社/メーカー: ダイヤモンド社
- 発売日: 2006/09/28
- メディア: 単行本(ソフトカバー)
- 購入: 215人 クリック: 3,105回
- この商品を含むブログ (115件) を見る
役に立った?
とりあえずの2級でしたが、出題範囲はある程度統計学の内容を網羅しているので、全体の知識整理になります。
とくに検定の知識は実務でも利用するケースが多く、どのようなデータに対して、どんな検定手法を使うべきか、考えるよい材料になりました。
まとめ
ということで、今日は統計検定について書いてみました。
データサイエンティストを目指す人にとっても、またそうでない人にとっても統計学は関わることが多い学問だと思います。
普段何気なく、平均値とか比較している方、少し統計入門の本を読んでみつつ、興味があれば試験を受けてみてはいかがでしょうか?
ではでは
イケてない企業あるある7選!!
どうも、ITコンサルタントのShoheiです。
今日はイケてない企業あるあるを上げていきたいと思います。
自社で感じたことや、周りの話から得たことを元に書いていきます。
とりあえず会議を長めかつ大人数で設定する
「よくわからないけど2時間とっときました」てインビテーションがくる会議は我慢大会のお誘いかなと思います。
またやたら人数が多い会議も、会議をお祭りか何かと勘違いしてるのかなと思っちゃいます。

集中の継続が可能な時間は、いろんな説がありますが、諸々調べてると、15分刻みが一つの周期で、大体45-50分程度で集中力が低下し始める、なんて説はいろんなところに見られました*1。
また超短期の集中力の話ですが、マイクロソフトの調査だと「人間の集中力は8秒で、金魚の9秒より短い」なんて説も出てます*2。
イケてる企業の一つであるGoogleの会議は基本30分、長くても50分、最大8人みたいですね。*3*4。
結論が出たのに会議を終えない
30分で結論が出たのに、90分ぐらいダラダラと話してる会議、カフェでの会話かなと思っちゃいます。
目的が明確になっていない会議ほどこんな目に合いがちです。
また、おしゃべり好きな営業さんなど、絶対お前喋りたいから引き伸ばしてるだろ、ってやつも時々います。

部下が何をやっているかわからないマネージャー
「上に言われてるから」「上に報告しなきゃいけないから」が唯一の行動理由となっているゴミマネージャーが見受けられます。あなたの仕事は伝言ゲームですかと思いますね。

なおマネジメントの意味は以下ですね
具体的には、組織の目標を設定し、組織を作ります。そして部下の動機付けやコミュニケーションをはかり、その部下を評価し、それを元に人材育成するという使命を持った役職です。*5
外資とかだと、マネージャーになるということは偉くなるということとも限らず、職種を変更するだけという意味合いだったりします。
イケてない企業だとマネージャーの素質がない人も年功序列で時が経つとマネージャーになったりしますよね。それがゴミマネージャーを生む要因になってたりもするかと思います。
職場環境が劣悪
これも我慢大会の類ですね。戦時中かなと思います。

事務処理が古典的
例えば社内承認に上司がサインをする文化。スピード感、コスト、信ぴょう性、全てに置いてウンコだと思います。
無能マネージャーへの形だけの説明、形だけの残業承認、このへんもウンコですよね。

営業が社内ヤクザ
お客さんの声を届けるってのは大事だと思うんだけど、それに会社が振り回されずに会社の意思で判断をしていくというのも重要ですよね。
こういうのに限って、営業は技術とか全くわからず調子よくお客さん先で出来ます出来ます言っちゃってるケースだったりするんですよねー。

重鎮絶対主義
最後はこれ。部の歴史だとか昔ながらのノウハウという名の重い束縛を抱え、そしてそれを周りに強要してくる重鎮という名のウンコの存在。
ノウハウ蓄積は大事だと思いますが、重要なものはシェアする仕組みを作らなければ意味がないと思います。またノウハウに縛られすぎて柔軟な判断が出来なくなると、みんなが思考停止してしまいます。
柔軟性の欠けた重鎮を生産してしまう前に、人事異動等で動かすべきだと自分は考えます。

まとめ
今日はイケてない企業あるあるを作ってみました。
Sierとコンサルタントの違い
どうもー、Keiです。
もう12月ですねー。寒くなってまいりましたので、風邪など引かないようにしてくださいね。

今回のトピックは「Sierとコンサルタントの違い」についてですが、意外と答えにくい質問だと思うのですよね。
特に、現在コンサルタントの方はSierとはぜんぜん違うよ、というプライドや意識を持っていたりして、自信を持って違いを言える方が多い印象です。
一方で、この2つの職業は具体的な業務内容が外からだと想像しにくい側面があるため、違いを明確に言うのは難しいと僕は思うのです。
特に、最近はコンサルもITコンサルのように戦略だけでなく、IT領域のPMOやSIをやるコンサルも出てきたため、両者の境界線が曖昧になっていると感じます。
ぼくは前にITコンサル系の会社の面接に行った際に、本当にこのブログのタイトル通りの質問をされたことがあります。
「コンサルとSierの違いってなんだと思う?」
しかも、その1社だけではなくて、
他のITコンサル系の会社からも、これと似た質問をもらったんですよね。
そのときは、コンサルはお客様から課題を聞いて、それに対して提案を~みたいな答えを返していましたが、今ならもう少し上手く答えられるかな、と思います。
この質問は、けっこうSIよりのITコンサルでは聞かれる質問みたいなので、自分の中で回答を持っているといいですね。
ぼくの考えは、このブログのもう少し後ろの方で書きます。
Sierのイメージ
まず、両者のイメージがないと違いも何もないですよね。
僕のSierのイメージを書き出してみます。
最後だけバイネームになってしまいましたが、こんな感じですよね。
あと、仕事を横に流すだけで仲介料ばっかり高くなる胡散臭いイメージもあります。
別に、ぼくはアンチSierではありませんよ。
Sierが多方面で叩かれているのは事実ですが。
余談ですが、暗い話題の多いSierですが、それを真摯に受け止めて今後Sierはどのように活躍すれば良いかについて、下記の本では非常に良くまとめられています。

これからのSierの話をしよう エンジニアの働き方改革 ThinkIT Books
- 作者: 梅田弘之
- 出版社/メーカー: インプレス
- 発売日: 2017/09/08
- メディア: Kindle版
- この商品を含むブログを見る
コンサルタントのイメージ
特にSierと違いが分けにくいITコンサルのイメージについてもばらばらと書いていきます。
- 激務
- クライアントへ提案する
- PM
- 技術はあまり詳しくない
- 胡散臭い
激務と胡散臭さが一致したイメージですね。
個人的に、というかクライアント的にはSierよりコンサルの方が何やっているかわからない、という場合もあるのではないでしょうか。
良くわからないが、ただの紙切れのために何千万、何億と払ったり、自社で
なんとかできないのか!?って思う方もいると思います。
Sierとコンサルタントの違い
さて、ここまでイメージの話ばかりしてきましたが、結局Sierとコンサルの違いはなくなりつつあると思います。
一方で、よくSierとコンサルタントが違うと言われているポイントについてコンサル目線で話をしたいと思います。
端的に言うと、コンサルはSierと違って仮説を持ってクライアントの課題に対して提案ができる点です。
ここでいう、課題が自明であればSierでも答えを提示するかもしれませんが、プロセスの決め方などやり方が多岐に渡る場合では、Sierはお客様に決めてもらうか、どのようなパターンがあるかをお客様に提示するに留まります。
一方で、コンサルは抜け漏れなく方法論のパターンを示した後、お客様の最適なプロセスはこれだろうという仮説を作成し、落とし所を作るという部分だと思います。
当たり前だろ、と思うかもしれませんが
この仮説を持つという部分とそれをお客様にキレイに見せる部分がコンサルの根っこの部分ではないかと考えます。
もちろん、Sierの人が何も考えず仕事をしている、とは言っているわけではありません。
あくまでロール上の話です。
さて、今回はSierとコンサルの違いについて話をしました。
就活中の方の参考になれば良いかと思います。
それではまた!
大規模データ処理を便利に実現するhadoopエコシステムって?
どうもkoheiです
気が付けば12月...今年も終わりですね。
今日は前回振れたHadoopについて、もう少し掘り下げて書きたいと思います。
前回のおさらい Hadoopはデータを貯めるにも加工も容易?
前回の記事でデータレイクとして使われるアーキテクチャとしてHadoopが主流になりつつあるという話をしました。
hadoopを使うことで下記の二つが期待できます。
1.分散ファイルシステム「HDFS」によってさまざまな形式のファイルを大容量で保存できる。
2. MapReduceやほかのHadoopエコシステムを通じて、HDFSに保存されているデータへのアクセス・加工が容易になる。
1. については、分散処理のところで少し説明しましたが、今回は2.のエコシステムというものを掘り下げて説明してきます。
Hadoopの構成
Hadoopは現在、大きく下記の3要素で構成されています。
HDFS: 巨大なファイルを分割して保存するファイルシステム
MapReduce: 分散サーバ上でのデータ処理を簡単にするためのプログラミングフレームワーク
YARN: 分散サーバ上の処理を管理し、MapReduceなどの分散処理を制御するソフトウェア

こうした要素を使うことで、比較的簡単に巨大なデータも、複数のサーバを使った分散処理が実現できるようになりました。やったね。おしまい。
・・・という形でHadoopは終わることはありませんでした。
便利なものはもっと便利にしよう!
という発想で、Hadoopをより便利に使うためのアプリケーションが次々に開発されていきました。
こうしたHadoopを中心とした便利アプリケーションの集まりをHadoopエコシステムと言うようになります。
Hadoopの弱点
エコシステムに触れる前に、その背景をもう少し掘り下げます。
Hadoopを使って比較的簡単に、分散処理ができるようになったと言いましたがいざ実際に使ってみようとするといろいろ困りごとが出てきます。
だいたいhadoopを使いたい人というのは、データ解析を主体とする人でそれほどプログラム開発メインではなく、もっと楽に使いたいという意思が強いです。
- HDFSはファイルを分散して管理するため、「特定ファイルの一部を書き換える」といったことをすると、処理のオーバーヘッドが大きい。小回りが利かない
HDFSは巨大なファイルを細かく分けてサーバにばらし、必要な時は一括で読み取って処理して、また別のファイルとして書き出す、という仕組み原則です。小さなファイルや部分的な変更を行うには処理が大掛かりになってしまいます。
-
一回で大容量のデータを処理する場合はいいが、複数サーバでデータを読み込んで処理して、まとめて、またサーバに戻して、書き込んで・・・とやっていると、繰り返し処理に時間がかかり過ぎ
MapReduceの都合上、データを読み込む、処理する、まとめる、ばらす、書き出すというステップを踏みます。ループ処理や機械学習などの反復計算が必要になると、速度的メリットがなくなります。。。いわゆるバッチ処理向きということです。
こうした弱点を補うべくHadoopエコシステムが作られていきます。
Hadoopエコシステム
Hadoopエコシステムと呼ばれるアプリケーションにはどんなものがあるのか、
試しにHadoopベンダーのHortonWorksのサイトを見てみます。
すると

見にくいですが、縦棒1本が一つのアプリケーションで、20以上も存在することがわかります。
さらに、Clouderaといった他のhadoopベンダもまた、別のエコシステムアプリケーションを開発しています(重複するものも多いですが)
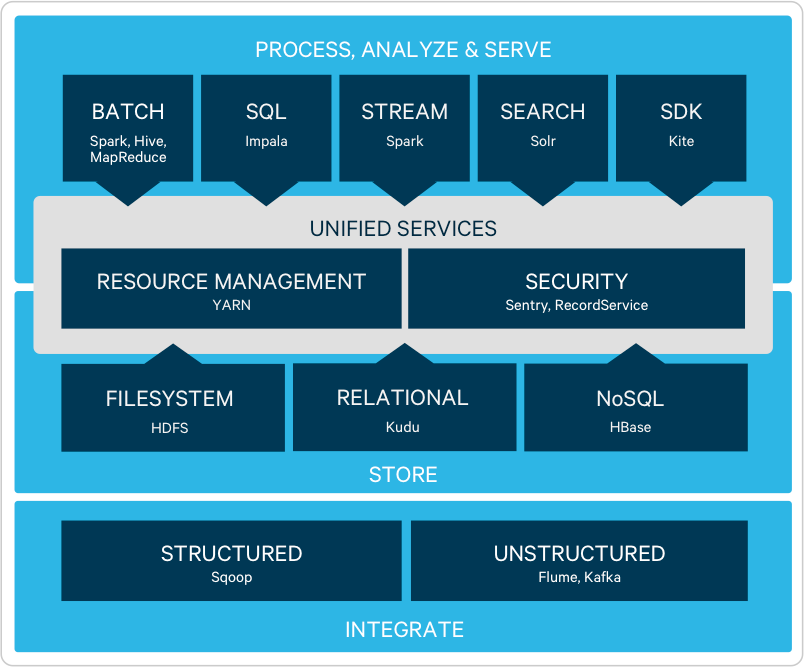
このようにhadoopベンダによってHadoopエコシステムの定義が若干変わります。。。
おまけに、新しく開発されるもの、開発が縮小していくものもあり、日々エコシステムは変化しています。
エコシステムのアプリケーションがたくさんあるので、この中で一つ目の課題
を解決すべく作られたものを紹介します。
Apaceh Hive: 分散処理をSQLで実現する

hadoop象が蜂の体とくっついててなかなかキモイですが
このhiveは、javaでゴリゴリ書かなくても、SQLで書いた処理を、MapReduce処理に変換してくれます。
Apaceh Pig: スクリプト言語で簡単にMapReduceを実行

次は豚です。象はいずこに
SQLではちょっと細かなところに手が届かないときはPigの出番です。
raw = LOAD 'excite.log' USING PigStorage('\t') AS (user, time, query);
clean1 = FILTER raw BY org.apache.pig.tutorial.NonURLDetector(query);
clean2 = FOREACH clean1 GENERATE user, time, org.apache.pig.tutorial.ToLower(query) as query;
pigのtutorialから抜粋しましたが、上記のように、データの入出力形式や、様々な加工処理をスクリプト言語の形で簡単に実行できます。
が、正直Hiveでかなりのことは網羅しているので、Pigはあまり見ません。
まとめ
Hadoopの構成と、その欠点、そしてhadoopエコシステムについて少しふれました。
次回エコシステムの他のアプリケーションを掘り下げたいと思います
ではでは
AmazonもLINEもメルカリも採用。マイクロサービスアーキテクチャって何?
どうも、ITコンサルタントのShoheiです。
こたつの季節がやってきましたね。今日はこたつからの更新です。
さて今日は、マイクロサービスアーキテクチャについて簡単に説明をしていきたいと思います。
マイクロサービスアーキテクチャとは
早速ですが、マイクロサービスアーキテクチャって聞いたことありますか?
僕は勉強するまで知らなかったのですが、多数の大手Webサービス提供会社が採用している有名なアーキテクチャです。タイトルに書いた企業の他にも、Netflix、クックパッド、Gunosy、ウォールマート、Twitterなども採用を公表しています。
これが何かを超絶端的に言ってしまうと、「多数機能を実現する大規模なサービスからシステムを作るのではなく、多数の独立したサービスの集合体からシステムを構成させるアーキテクチャ」のことです。イメージは下の絵です。

もう少し説明するよ
もう少しだけ、ざっくりですが説明しましょう。
サービスを分離する指針は?
基本的なサービス指針としては、以下のようなものが挙げられます。
- サービスの境界をビジネスの境界に合わせる。 (独立・重複なし、1サービス1ビジネス機能)
- 一つのサービスを複数の組織で開発しない
- 他のサービスの変更をせずに、単独でサービスの変更やデプロイが行えるようにする
- 各サービスのコード数の規模感は「2週間で書き直せるもの」程度にとどめる
サービス同士はどうやり取りする?
いくつかやり方があるのですが、例えばREST APIなどを利用することで、他サービスから情報を得たり、他情報に情報を与えたりしています。
重要なことは、下の図のようにあるサービスが他サービスの内部事情を知る必要がない仕組みにしておくことです。

主なメリット
では、このアーキテクチャを導入するメリットを説明しましょう。
実装技術が異なっても良い
例えば、サービスAは実装にjavaを使うが、サービスBにはrubyを使うだとか。
サービスごとに独立をしているので、技術も異なって問題ありません。
また、何か新しい技術が出た時、全体を置き換えるにはリスクがある、といった場合にも、あるサービスに閉じて導入ができるので、迅速に最新技術の導入が進められるというのもメリットです。
独立してスケーリングできる
以下のようなケースの場合にスケールアップ考える場合、モノシリックシステムでは、ボトルネックとなっているサービス以外も一緒にスケールさせていく必要があります。
- サービスAの利用数がかなり増えてきた
- 土日だけサービスBの利用者量が増える
一方でマイクロサービスアーキテクチャでは、リソースが逼迫しているサービスだけインスタンスを拡張するなどといった局所的スケーリングが可能となります。
機能追加にかかるタスクを小さくできる
モノシリックシステムでは、特定の部分に小さな変更を加えたとしても、他の様々な部分に影響を与えてしまう可能性があります。そのためテストを入念に実施する必要が出てきたり、それがゆえに各機能でまとめてリリース作業をしたりします。しかしそれではスピード感が損なわれる上、まとめてのリリースは変更差分が大きくなるのでリスキーです。
その点マイクロサービスアーキテクチャでは、他サービスとのやり取りに使うAPI仕様などを変更しない限りはあるサービスに閉じた変更が可能なので、スピーディーな変更に対応ができます。
再利用可能
例えば、上の図はInstagramのような写真投稿のシステムのイメージでサービスA/B/Cを書いてみましたが、その会社で新たに動画投稿のサービスを作ろうと思った場合。
モノシリックシステムでは全て作り直しになりますが、マイクロサービスアーキテクチャではサービスごとに独立しているので、例えばサービスBの部分は新システムでも使いまわそうといった、個別での再利用が可能となります。
書籍紹介
マイクロサービスアーキテクチャといえば、この本です。
ただ、THE・和訳本て感じで、すごく辛いです。内容もかなりタフです。

まとめ
今日は簡単ですがマイクロサービスアーキテクチャについて説明をしました。
次回は少しだけ突っ込んで、実際にあるサービスの構造を見ていきましょう。
議事メモを制するものはプロジェクトを制す(小並)
どうも、Keiです。
皆様、毎日本当にお疲れ様です。

今日は初心に帰って「議事メモ」を取り上げてみます。
皆様、「議事メモ」ってなんでしょう?
「議事録」でもなく単なる「メモ」でもない。「議事メモ」
会社や部署、チーム単位でも独自ルールがあると思うのですよね。
そして、たいてい会社の若手が最初に担当する仕事ですよね。
今回はそんな「議事メモ」について、今一度書く目的を振り返って、何を書けばプロジェクトのためになるかを書いていきたいと思います。
自分の忘備録的なところもあります。
「議事メモ」を書く理由
まず、これがはっきりしていないと書くモチベーションもわかないですし、後から見返したときに必要な情報がない!なんて状況になってしまいます。
「形式的に昔からみんな書いてるから」なんて現世にいないと思いますが、そんな場合は書く必要があるかどうかのレベルから見直すべきです。
さて、議事メモを書く際には大きく以下の目的があるかと思います。
- 証拠能力
- ToDo、アクションアイテムの明確化
- 全体の意識合わせ(齟齬がないか)
もちろん、上の全てが目的の場合もありますし、1つだけの場合もあるでしょう。
証拠能力
会議中の発言はホワイトボードやディスプレイ上で記録していても、後からテキストで共有しないと「言った言わなかった問題」が発生する場合がありますよね。
これを避けるために、証拠として議事メモを会議に参加した全員に共有します。
ToDo、アクションアイテムの明確化
会議中の議論は発散を経て、収束することが多いかと思いますが、会議後に「誰」が「何」を「いつ」までにするのかが意外に明確になっていない場合があります。
そのため、議事メモでそこを明確化することで、次のアクションが明確になります。
全体の意識合わせ
会議中は決まった!と思っても実は認識がズレていた。。なんてことが特に会議時間が短い場合はあるかもしれません。
こんなときに議事メモを共有して齟齬がないことを確認することができます。
(大事な会議を短い時間でやったり、後で議事メモで齟齬が出たりは最悪ケースなので、こういうのは会議のファシリテートで解決すべきですけどね。大事な会議だから、会議の最後のまとめの時間を増やしたりとか。こういうケースでは、議事メモは転ばぬ先の杖的な利用をすると良いと思います。)
議事メモの中身
さて、上記のように議事メモを書く目的が複数あるように、議事メモの書き方(中身)も目的に合わせた書き方があることがわかると思います。
例えば、本当に「誰」が’「何」を言ったのかの証拠能力だけを議事メモに求めるなら、議事メモは音声データだけで良いと思います。
一方で、同時にToDoも明確化したいし、認識の齟齬も出したくない場合がほとんどだと思うので、議事メモを見てわかりやすいように、構造化したり、ToDoアクションアイテムを前出ししたりするのですよね。
フォーマット
上述した3つの目的を満たすためには、一般的な議事メモとしては下記があれば良いかと思います。
ヘッダ
- 会議名
- 日付
- 参加者
- 場所
コンテンツ
- ToDoアクションアイテム
- メイントピック(省略可)
- その他議事メモ(省略可)
まあ、ぶっちゃけ何の変哲もない議事メモの構成ですよね笑
議事録でなく、議事メモの場合は個人的にはToDoアクションアイテムがしっかりと書かれていると良いかと思います。
「メイントピック」や「その他議事メモ」は、上述した証拠能力を持たせるためにいるようなもので、この人がこう言ったことを記録に残し、協調したいときに使用するべきかと思います。
なので、よく「その他の議事メモ」に自分がメモした内容を延々と書き連ねる人がいますが、個人的には意味がないと思っています。なぜなら、それを書く目的が薄いために、読み手へ伝えたいものがないからです。
この場合、議事メモの目的イメージがあってないと、読む方も証拠能力があるからと全て読まなければならないので、時間の無駄です。
時間と構造化
もう一つ、ぼくが議事メモを書く際に気を付けたいことが2つあります。
「時間」と「構造化」です。
時間
特に議事メモの場合、メモでいいから早く全員に共有して、ToDo・アクションアイテムをはっきりさせて、各々が動けるようにしようという意味合いもあるので、議事メモの作成に1時間以上かけるのは避けたいです。
なんなら、会議中に書いたものをそのまま上司のレビューに回すくらいの速さと完成度が求められます。
しかし、特に若手やチームが変わったばかりだと、誰の発言が重要かわからなかったり、知らない単語のオンパレードで聞き逃したり等あると思います。
そのため、レビューを含めて1時間以内には終わるように会議の前から段取りを立てておくことも大事かと思います。
議事メモにそこまで、、と思うかも知れませんが、
自分の業務のキャッチアップにも繋がりますし、書いた議事メモが後で見返されることになることも知れません。
しっかりとした議事メモを作成することは非常に重要です。
構造化
テクニックというか、皆さん無意識のうちにやっているかと思いますが、ポワポ・ワードが必須であるこの現代、インデントを使ってトピックをキレイにまとめる構造化をしない人はいないかと思います。
一方で、議事メモを発言順にばあ~~っと書いていた人はこの構造化が出来ていない人です。
ここで、難しいのが「時間」と「構造化」の両立です。
構造化は、グルーピングのようなもので同じ話題を同一のインデントで分けて書くことで見やすさ、頭の整理をするものです。
しかし、会議の議論中では各々が五月雨式に意見を言うため、そのままメモを取るともちろん構造化ができません。
そのため、会議中に議事メモを作成する場合は、発言をそのままメモをとるのではなく、構造化しながら要点をまとめる必要があります。
個人的に議事メモをとる速度はプロジェクトの習熟度と比例すると思いますが、構造化をするスピードが上がると、プロジェクトの理解度が浅くても、議事メモをとるスピードは平均的にあがると思います。そして、そのプロジェクトのキャッチアップのスピードも。
さて、いかがだったでしょうか。
今回は議事メモについてまとめました。また次回!