大規模データ処理を便利に実現するhadoopエコシステムって?
どうもkoheiです
気が付けば12月...今年も終わりですね。
今日は前回振れたHadoopについて、もう少し掘り下げて書きたいと思います。
前回のおさらい Hadoopはデータを貯めるにも加工も容易?
前回の記事でデータレイクとして使われるアーキテクチャとしてHadoopが主流になりつつあるという話をしました。
hadoopを使うことで下記の二つが期待できます。
1.分散ファイルシステム「HDFS」によってさまざまな形式のファイルを大容量で保存できる。
2. MapReduceやほかのHadoopエコシステムを通じて、HDFSに保存されているデータへのアクセス・加工が容易になる。
1. については、分散処理のところで少し説明しましたが、今回は2.のエコシステムというものを掘り下げて説明してきます。
Hadoopの構成
Hadoopは現在、大きく下記の3要素で構成されています。
HDFS: 巨大なファイルを分割して保存するファイルシステム
MapReduce: 分散サーバ上でのデータ処理を簡単にするためのプログラミングフレームワーク
YARN: 分散サーバ上の処理を管理し、MapReduceなどの分散処理を制御するソフトウェア

こうした要素を使うことで、比較的簡単に巨大なデータも、複数のサーバを使った分散処理が実現できるようになりました。やったね。おしまい。
・・・という形でHadoopは終わることはありませんでした。
便利なものはもっと便利にしよう!
という発想で、Hadoopをより便利に使うためのアプリケーションが次々に開発されていきました。
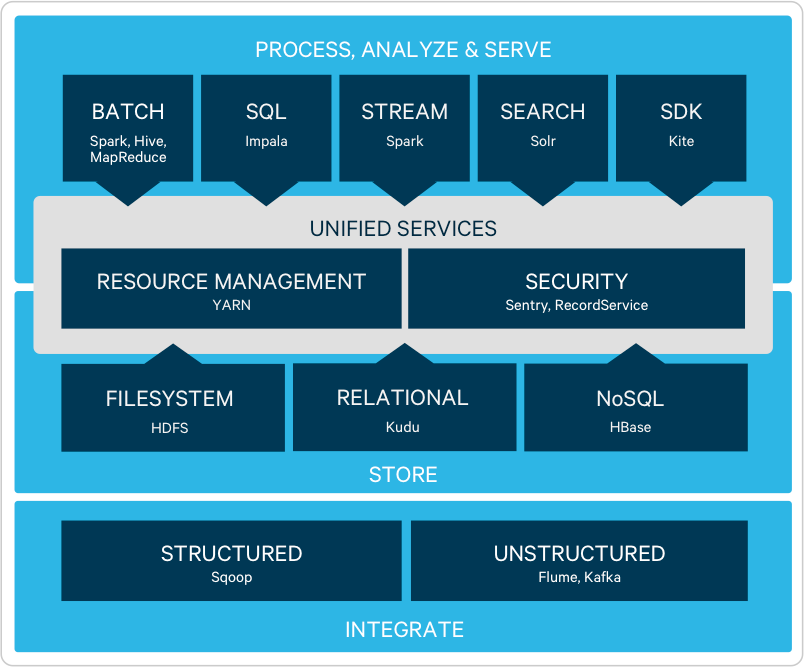
こうしたHadoopを中心とした便利アプリケーションの集まりをHadoopエコシステムと言うようになります。
Hadoopの弱点
エコシステムに触れる前に、その背景をもう少し掘り下げます。
Hadoopを使って比較的簡単に、分散処理ができるようになったと言いましたがいざ実際に使ってみようとするといろいろ困りごとが出てきます。
だいたいhadoopを使いたい人というのは、データ解析を主体とする人でそれほどプログラム開発メインではなく、もっと楽に使いたいという意思が強いです。
- HDFSはファイルを分散して管理するため、「特定ファイルの一部を書き換える」といったことをすると、処理のオーバーヘッドが大きい。小回りが利かない
HDFSは巨大なファイルを細かく分けてサーバにばらし、必要な時は一括で読み取って処理して、また別のファイルとして書き出す、という仕組み原則です。小さなファイルや部分的な変更を行うには処理が大掛かりになってしまいます。
-
一回で大容量のデータを処理する場合はいいが、複数サーバでデータを読み込んで処理して、まとめて、またサーバに戻して、書き込んで・・・とやっていると、繰り返し処理に時間がかかり過ぎ
MapReduceの都合上、データを読み込む、処理する、まとめる、ばらす、書き出すというステップを踏みます。ループ処理や機械学習などの反復計算が必要になると、速度的メリットがなくなります。。。いわゆるバッチ処理向きということです。
こうした弱点を補うべくHadoopエコシステムが作られていきます。
Hadoopエコシステム
Hadoopエコシステムと呼ばれるアプリケーションにはどんなものがあるのか、
試しにHadoopベンダーのHortonWorksのサイトを見てみます。
すると

見にくいですが、縦棒1本が一つのアプリケーションで、20以上も存在することがわかります。
さらに、Clouderaといった他のhadoopベンダもまた、別のエコシステムアプリケーションを開発しています(重複するものも多いですが)
このようにhadoopベンダによってHadoopエコシステムの定義が若干変わります。。。
おまけに、新しく開発されるもの、開発が縮小していくものもあり、日々エコシステムは変化しています。
エコシステムのアプリケーションがたくさんあるので、この中で一つ目の課題
を解決すべく作られたものを紹介します。
Apaceh Hive: 分散処理をSQLで実現する

hadoop象が蜂の体とくっついててなかなかキモイですが
このhiveは、javaでゴリゴリ書かなくても、SQLで書いた処理を、MapReduce処理に変換してくれます。
Apaceh Pig: スクリプト言語で簡単にMapReduceを実行

次は豚です。象はいずこに
SQLではちょっと細かなところに手が届かないときはPigの出番です。
raw = LOAD 'excite.log' USING PigStorage('\t') AS (user, time, query);
clean1 = FILTER raw BY org.apache.pig.tutorial.NonURLDetector(query);
clean2 = FOREACH clean1 GENERATE user, time, org.apache.pig.tutorial.ToLower(query) as query;
pigのtutorialから抜粋しましたが、上記のように、データの入出力形式や、様々な加工処理をスクリプト言語の形で簡単に実行できます。
が、正直Hiveでかなりのことは網羅しているので、Pigはあまり見ません。
まとめ
Hadoopの構成と、その欠点、そしてhadoopエコシステムについて少しふれました。
次回エコシステムの他のアプリケーションを掘り下げたいと思います
ではでは